Lecture 11: Page Rank
Previously, we have only had one metric for whether a document is a good fit for a query , that was . However in cases of huge document corpuses, there may be too may values of for which is large.
One assumption that must be broken to tackle this problem is that all documents are equal, they are not. Wikipedia is more likely to answer your query than one's personal web page.
Note: Page Rank is named after Google's Larry Page not web page
We assign a prior probability to each document in our corpus. We can think of as the probability that is relevant to before the user creates query .
Whether is returned in response to query depends on and . We treat as the Page Rank of
Cases where document retrieval is based solely on we effectively assume to be the same . This case is referred to as equal priors
Constructing Priors
We can change our relevance assumption to be that the relevance of any document ot a query is related to how often that document is accessed.
Such as comparing academic papers by their citation index. This is an example of a self-evaluating group whereby each member evaluates all other group members.
Definition of a Markov Model
A -state Markov Model consists of:
- A set of states
- An initial state probability distribution
where is the probability that the model starts in state and
- A state transition probability matrix, , where is the probability of a transition from state to state at time
where
From the initial state probability distribution and the state transition matrix, you can draw a Transition Diagram such as:
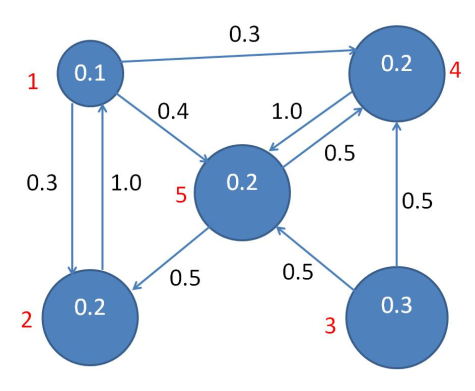
State probability distribution at time
The state probability distribution at time is , similarly, at time the PD is .
What happens at time in general and what happens as
In order to calculate th state probability distribution at time 1, you must calculate and sum the probability of being at each state given a previous (or starting) state. The starting state could be any state. Diagrammatically this can be seen:
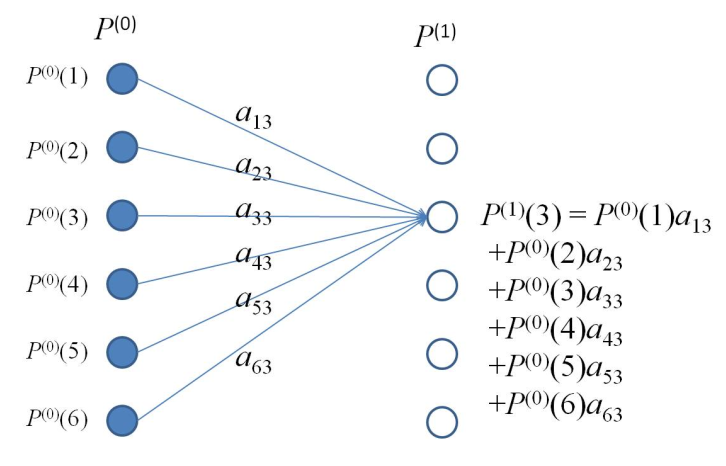
In matrix form this can be written:
and more generally,
Suppose that as or the probability distribution plateaus over time, then:
or, is an eigenvector of with an eigenvalue of 1
Analysis
Interestingly, we can encode an 'exit' state into our initial state probability distribution, by definining an initial spd as :
with a corresponding transition matrix. Our state probability distribution will converge to:
Convergence
Do our state probability distributions always converge as ? not
Conditions for convergence of Markov Processes
Note not expected to be known
- The model must be irreducible, i.e. for every pair of states there must be a time and a state sequence with and . Essentially, it is possible to get from state to via the state sequence with a non-zero probability.
- The model must be aperiodic, a state is aperiodic if the HCF of the set of return times for the state must be 1. A model is aperiodic if all of its states are aperiodic.
Simplified Page Rank
Given a set of documents we define:
- as the set of pages pointing to
- as the number f hyperlinks from
With this the simplified Page rank for document is given by:
As this equation is recursive we instead write:
We can formulate this in matrix form:
Let be the matrix whose entry is given by:
Let be the column vector whose entry is then:
We can therefore define:
Simplified Page Rank: Markov model interpretation
We can implement Simplified Page Rank using a Markov model where:
I.e. is the initial estimate of Page Rank, is the transpose of the state transition probability matrix
means that
"Damping Factor"
To this point all authority of a page comes from the pages that have hyperlinks to it. I.e. a page with no hyperlinks to it will have an authority of 0. This breaks with the first requirement for Markov convergence, irreducibility.
To solve this problem, we introduce a damping factor . Where os the proportion of authority that a page gets by default.
Our simplified Page rank equation now becomes:
Where is a column vector of 1s
Convergence
is a system of equations with unknowns. We can re-write this as a dynamic system:
When considered in this way we can see that it converges for any initial condition to a unique fixed point s.t.
Dangling Pages
A page which contains no hyperlinks to other pages is referred to as a dangling page as in a tree-based representation they form the leaf nodes.
If is a dangling page the the column of consists of entirely 0s. the sum of the column sums to 0 and is no longer a column stochastic matrix. Cases such as these can break some of our earlier analysis.
One solution to dangling pages is to introduce a dummy page and add a link to to every previously dangling page.
We then extend our transition matrix to get a new matrix and create a new dangling page indicator where:
We add as the bottom row of and add an additional column of 0s followed by a single 1 so that our new transition matrix becomes:
Here you can see that each dangling page has a hyperlink to and has only a link to itself.
An alternative solution is to create links from dangling pages to all pages. Here we construct a matrix with equal rows
Finally we construct an matrix of of the form:
With this new transition matrix our page rank equation becomes:
Probabilistic Interpretation of Page Rank
We can essentially think of each page as a state in a Markov model or a node in a graph. Each note or state is connected via a hyperlink structure. Each Connection between a node and is weighted by the probability of its usage. These weights depend only on the current node, not on the path to it; this is a property of Markov decision chains.