Lecture : Linear Discriminant Analysis
PCA vs LDA
Principal Components Analysis finds the direction of maximum variance for a dataset .
If each datapoint falls into one of a distinct number of classes , PCA does not utilise this information to better separate the data.
LDA
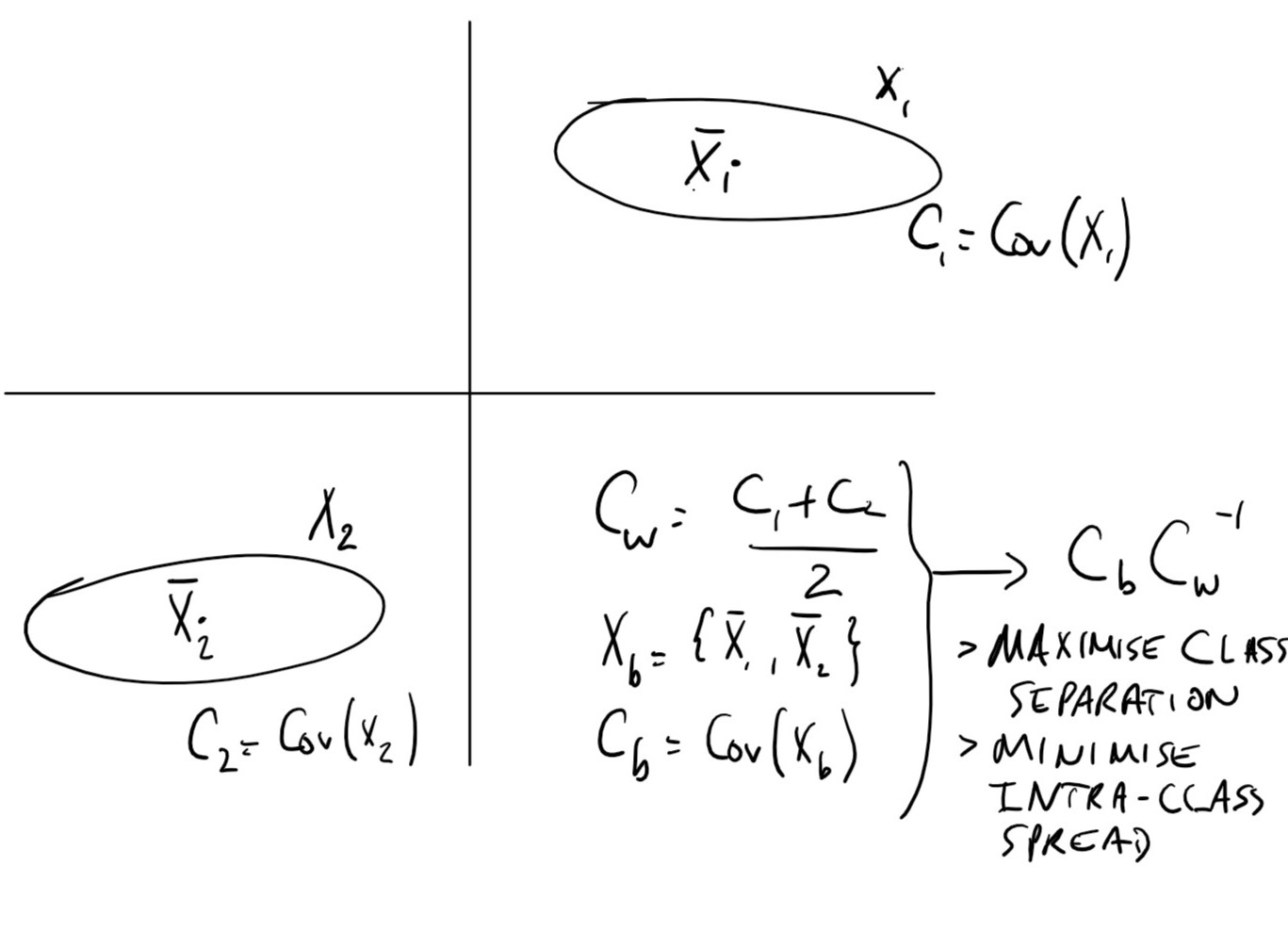
In this case where we have a dataset where each point belongs to one of classes, let be the set of data points in that belong to the class .
Let be the covariance matrix of the dataset , we define the average within-class covariance matrix as:
Let be the a row matrix where the row is the average of the vectors in . The between-class covariance matrix is the covariance matrix
In order to separate the classes we want to find a direction in the vector space that simultaneously:
- Maximises the between-class variance
- Minimises the within-class variance
The vector that satisfies these requirements is the eigenvector of corresponding to the largest eigenvalue.
Diagrammatic Example
LDA vs PCA
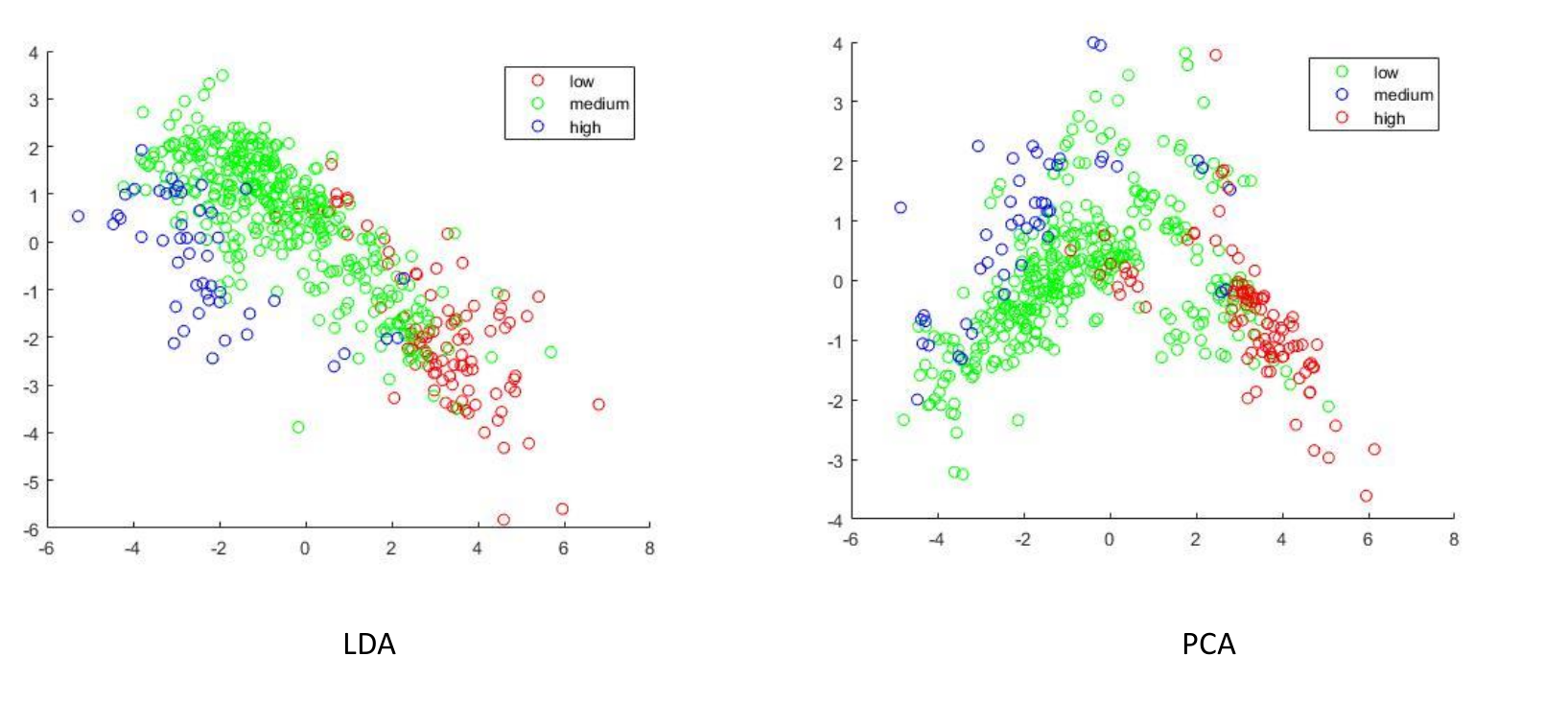
Here you can see that the split of the data is much more defined using LDA with entire sections being entirely populated by a single class.