Lecture 7: Latent Semantic Analysis
Vector Notation for Documents
Given a set of documents , we can consider this a corpus for information retrieval (IR). Suppose the number distinct words in the corpus () is , this is our vocabulary size.
If we split each document into different terms, we can write . Finally, we assign a frequency to each term s.t. term occurs times.
With this, the vector representation, of is the dimensional vector:
where:
- is the weighting calculated from term frequency the inverse document frequency, i.e. and the denotes the place term.
Latent Semantic Analysis (LSA)
Suppose we have a corpus with a large number of documents, for each document the dimension of the is potentially in the thousands.
Suppose one such document contained the words 'sea' and/or 'beach'. Intuitively, often, a document contains 'sea' it will also include 'beach'.
Mathematically, if has a non-zero entry in the 'sea' component/ dimension, it will often also have a non-zero entry in the 'beach' component.
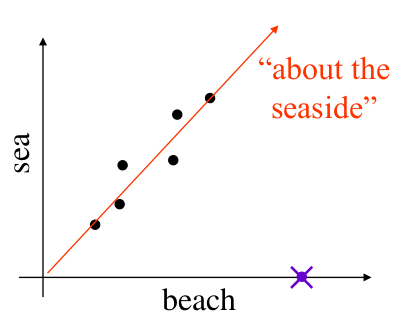
Latent Semantic Classes
If it is possible for us to detect such structures as the one seen above, then we can start to discover relationships between words automatically, from data.
The above example can be described as an equivalence set of terms including 'beach' and 'sea' which is about the seaside
Finding such classes is non-trivial and involves some relatively advanced linear algebra; the following is only an outline of which.
Steps
-
Construct the word-document matrix
The word-document matrix is the matrix whose row is the document vector of the document in the corpus. -
Decompose using Singular value decomposition (SVD)
This is a common function found in packages such as matlab or Julia's Linear algebra module.
This process is similar to that of eigenvector decomposition, an eigenvector of a square matrix is a vector s.t. where is a scalar.
For certain formations of we can write where is an orthogonal matrix and is diagonal.- The elements of are the eigenvalues
- The columns of are the eigenvectors
One can think of SVD as a more general form of eigenvector decomposition, which works for general matrices
In SVD we re-write as
Interpretation
The matrices and are orthogonal with real numbered entries.
- is where is the number of documents in the corpus.
- is where is the vocabulary size
- They satisfy:
- The singular values are positive and satisfy
- The off-diagonal values of are all 0
The columns of are dimensional unit vectors orthogonal to each other. They form a new orthonormal basis for the document vector space. Each column of is a document vector corresponding to a semantic class, or topic, in the corpus. The importance of the topic is given by the magnitude of
As is a document vector, its value corresponds to the TF-IDF weight for the term in the vocabulary for the corresponding document or topic. Using this we can work out how important to a topic the term in a document vector is to a topic . If is large then it plays an important role in the topic.
While describes topics as combinations of terms/ words, describes topics as a combination of documents.
Topic-based representations
The columns of , are an orthonormal basis for the document vector space.
If is a document in the corpus then is the magnitude of the component of in the direction of , i.e. the component of corresponding to topic . Therefore, it follows that:
is a topic-based representation of in terms of
Topic-Based dimension reduction
Since the singular values indicate the importance of the topic , we can therefore, truncate the vector when becomes small or insignificant.
where is the matrix comprised of the first columns of
We can now say that is a reduced dimensional vector representation of the document
Topic based word representation
Suppose is the word or term in the vocabulary.
The one-hot vector is the vector:
Note: a one-hot vector is a vector where only one row has a non-zero value.
is essentially the document vector for a document consisting of just the word
We can use to find the vector that describes in terms of the topics that it contributes to:
Where is the matrix comprised of the first columns of
Intuitively, given two synonymous we would expect that they would contribute similarly to similar topics, and as such we would expect and to point in similar directions. is often referred to as a word embedding