Lecture 9: Self-Organising Maps
-means Clustering
This is an iterative algorithm for grouping data into distinct sets.
Algorithm
- Estimate the initial centroid values
- Set
- calculate
- :
- Let be the set of that are closest to
- Define to be the average of the data points in
- i++, return to step 3
See slides for examples
Optimality
We can now ask the question: is the set of centroids, created via -means globally optimal? I.e. does the following hold?
No! -means is only guaranteed to find a local optimum with it's final result being dependent on the initial centroid guesses
Alternative to -means
In -means we calculate the distances between all data points and all centroids before any update takes place. Instead, we can update centroid locations based on seeing a single data point
'Online' Clustering
Online clustering updates centroids with each sample using the following equation:
Where is the learning rate.
- If is too small convergence will be too slow
- If is too big, algorithm will be unstable
Our solution to this is to start with a big value of and to shrink it over time.
Where is the time scale, determining how fast will decrease.
This process is similar to that of annealing
Algorithm
-
Choose the number of centroids,
-
Randomly choose an initial codebook
-
:
- Find the closest centroid
- Move closer to x_n
where is a small learning rate that reduces with time as determined by the equation:
where is the timescale
Enhancements to Online Clustering
- Batch Training: accumulates changes to centroids over small subsets of the training set
- Stochastic batch training: accumulates changes to centroids over small randomly chosen subsets of the training set
Neighbourhood Structure
Neighbourhood structuring is the process by which each point in the centroid set is connected it's nearest neighbours. The number of neighbours that it is directly connected to depends on the number of dimensions the structure is imposed for.
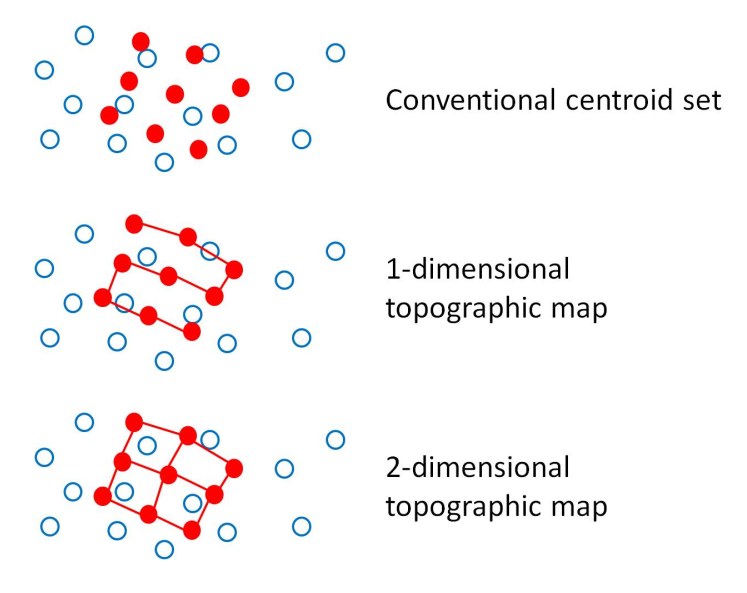
We can imagine the connections between these centroids in a neighbourhood as elastic bands whereby when we move one centroid closer to a data point to further reduce the distortion of the dataset we also move all other centroids by an amount proportional to how closely connected each centroid is to the one we just directly moved.
1 Dimensional Neighbourhood Structure
In 1 Dimension each centroid is directly connected to one other centroid, with ultimately each centroid being connected to all other centroids in the neighbourhood.
To define a neighbourhood structure you require a definition of distance between the members of the neighbourhood.
So for a neighbourhood centered on centroid with distance we can define the set of all other centroids where the indices of the centroids are less than or equal to as:
An illustration of a 1D neighbourhood defined with a range of distances can be seen below
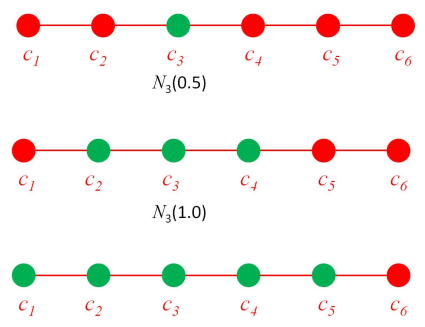
Note that these neighbourhoods are defined on the centroid index not the centroid coordinates!
2 Dimensional Neighbourhood Structure
Similarly we can define our neighbourhood structure in 2 dimensions with the equation:
Constrained Clustering
The aim of Constrained clustering using self-organising or topographic maps is to discover dimensional structure of high dimensional data by clustering whilst constraining our centroids to lie in a dimensional 'elastic'
Where the dimensions are the dimensionality of the neighbourhood structure.
Recalling our equation for Online Clustering
We can now define our update rule for Constrained clustering using a topographic map as:
Where indicates how close the centroid is to the centroid closest to
What do we choose for ?
Any candidate function must satisfy:
- decreases as becomes further away from
One possible function is:
Where is the neighbourhood width or strength of the elastic
In choosing a value for we can employ Simulated Annealing whereby we initially choose a high value to allow for broad cooperation between centroids but gradually reduce the value as the algorithm runs.
One scaling factor could be:
where is the timescale and is the initial neighbourhood weight