Lecture 8: Constraint Handling in Evolutionary Algorithms
Motivation
Spring Design
to minimise the weight of a tension/ compression spring. All design variables are continuous.
- Minimum deflection
- Shear stress
- Surge frequency
- Diameters
Let the wire diameter , the mean coil diameter and the number of active coils . The following are the constraints on these variables:
We can write this as a function to minimise:
which is subject to the following:
Engineering Optimisation
Also known as Design Optimisation, this is the process to find the combination of design variables that optimises the design objective and satisfies the constraints.
A design variable is under the control of the designer and could have an impact on the solution of the optimisation problem. They can be:
- Continuous
- Integers
- Sets of variables, often taken from a list of recommended values from design standards
Design objectives represent the desires of the designers such as to maximise profit or minimise cost
Constraints are desires the designers cannot optimise infinitely due to:
- Limited resources such as budget or materials
- User requirements or regulations
A design constraint is usually rigid or hard as they often need to be strictly adhered to.
Engineering optimisation problems fall under constrained optimisation problems
Constrained Optimisation Problems
In general a constrained optimisation problem can be represented as:
subject to:
where is the dimensional vector , is the objective function, is the inequality constraint and is the equality constraint
We denote the search space as and the feasible space as . The global optimum of might not be the same as that of
Types of Constraints
There are two main types of constraints we will look at:
- Linear Constraints: relatively easy to deal with
- Non-linear Constraints: can be much harder to deal with.
Constraint Handling in Evolutionary Algorithms
- The purist approach: rejects all infeasible solutions in search
- The separatist approach: considers the objective function and constraints separately
- The penalty function approach: converts a constrained problem into an unconstrained one by introducing a penalty function into the objective function.
- The repair approach: maps (repairs) an infeasible solution into a feasible one
- The hybrid approach: mixes two or more above approaches
Penalty Function Approach
There are 3 sub approaches under the penalty function method:
Static Penalties
The penalty function is pre-defined and fixed during evolution
The general form of static penalty function is:
where are fixed, predefined values
Equality constraints can be converted into inequality contraints:
Where but is small
This approach is simple to implement but requires rich domain specific knowledge to accurately set
can be divided into a number of different levels. When to use each level is determined by a set of heuristics, such as the more important the constraint, the larger the value of
Dynamic Penalty Functions
Dynamic Penalty Functions take the general form:
Where and are two penalty coefficients
The general principal of DPFs is that larger the generation number , the larger the penalty coefficients and
Common Dynamic Penalty Functions
Common Dynamic Penalty Functions include:
- Polynomials:
- Where and are user-defined parameters
- Exponentials:
- Where and are user-defined parameters
- Hybrid:
Application
Given a static penalty function where and
How does affect our training?
For a minimisation problem using for two individuals and , their fitness values are not determined by changing fitness values
Fitness proportional selection: As we now have changing fitness values we, by extension, have changing selection probabilities.
Ranking Selection:
- increasing will eventually change the comparison
- Decreasing will eventually change the comparison.
From this we can see that different values lead to different ranking of individuals in the population.
The use of different penalty functions lead to different objective functions and therefore different explorations of the search space, finding different optima.
Essentially, penalty function transform fitness and change the ranking system leading to different candidates being selected.
Inappropriate penalty function lead to infeasible results, setting is difficult
Part 2
Stochastic Ranking
Proposed by Prof. Xin Yao a lecturer at the University of Birmingham in 2000
This is a rank-based selection scheme that handles constraints
It does not use penalty functions and is self adaptive
Ranking Selection
Sort a population of size from best to worst, according to their fitness values:
From this set we select the top -ranked individuals with probability where is a ranking function such as:
- Linear Ranking
- Exponential Ranking
- Power Ranking
- Geometric Ranking
Penalty functions essentially perform a transformation of the objective, fitness function. A rank change a selection change.
Here we instead change the rank directly in the Evolutionary Algorithm.
We can view ranking as the same as sorting. We can modify the sorting algorithm in the EA to consider constraint violation.
Stochastic Ranking is essentially a modified form of bubble sort with some additional rules to handle constraints
Stochastic Ranking Algorithm
for j:=1 to M: for i := 2 to M: u := U(0;1) # randomly uniformly distributed random number if G(x'[i-1]) = G(x'[i]) == 0 or u <= P_f : # Swap values so that better (smaller) are before the larer ones if f(x'[i-1]) < f('[i]): swap(I[i], I[i-1]) swap(f(x'[i]),f(x'[i-1])) swap(G(x'[i]),G(x'[i-1])) else: if G(x'[i-1]) < G(x'[i]): swap(I[i], I[i-1]) swap(f(x'[i]),f(x'[i-1])) swap(G(x'[i]),G(x'[i-1]))
Where:
- is the number of individuals
- is the indicies of the individuals
- is the sum of constraint violation
- is a constant that indicates the probability of using the objective function for comparison ranking.
Why do we introduce given that is allows for infeasible solutions, in the cases where their fitness values are higher than feasible ones, with some probability?
Where : Most comparisons are based solely on infeasible solutions are likely to occur.
Where : Most comparisons are based on infeasible solutions are lss likely to occur, however, the resulting solutions may be poor
Recommended values of fall between 0.45 and 0.5
If penalty functions perform fitness transformation, converting rank change to selection change. Stochastic ranking changes ranks by changing the sorting algorithm. Why do we not change selection directly in the EA?
Feasibility Rule
- Based on binary tournament selection
- Having selected 2 random individuals to form a binary tournament, apply the following rules:
- Between 2 feasible solutions, the one with the better fitness value wins
- Between a feasible and infeasible solution, the feasible solution wins
- Between two infeasible solutions, the one with the lowest value for wins
This method is simple and parameter free, however, it can lead to premature convergence.
The Repair Approach to Constraint Handling
Instead of modifying an EA or fitness function, infeasible individuals can be repaired into feasible ones
Let be an infeasible individual and be a feasible one.
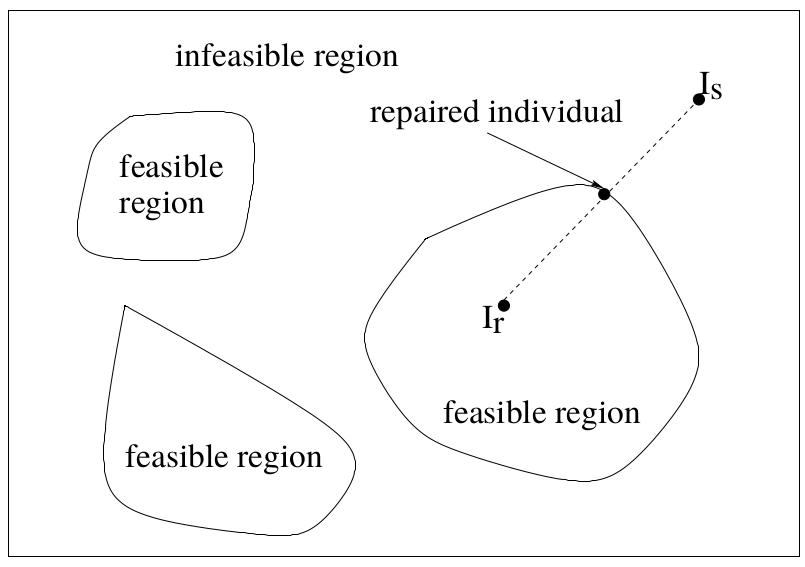
Repairing Infeasible Individuals
For this process we maintain two populations:
- A population of evolving individuals, feasible or infeasible.
- A population of feasible reference individuals, subject to change but not evolution.
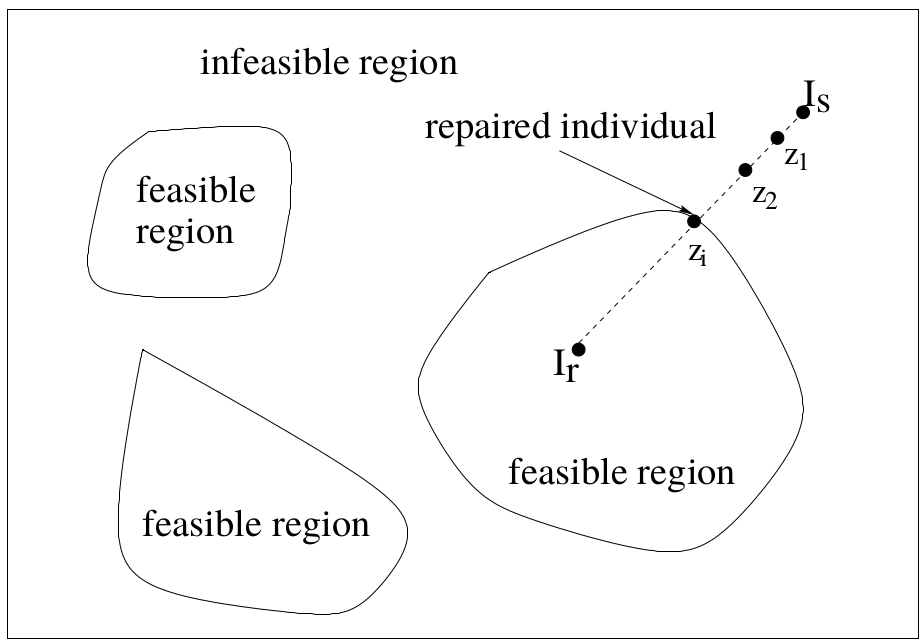
Algorithm
I_r = select a reference individual do until individual z_i is feasible{ z_i = a_i * I_s + (1-a_i)* I_r, where 0<a_i < 1 calculate the fitness value of z_i : f(z_i) if f(z_i) <= f(I_r) then replace I_s with z_i else{ u = U(0;1) // uniformly distributed random number if u <= Pr then replace I_s with z_i } }
Notice we replace with with some probability even though is worse than
Implementation Issues
- How do we find our initial feasible individuals?
- Premliminary exploration
- How do we select
- (uniformly) randomly
- according to it's fitness
- According to the distance between and
- How do we determine
- Uniformly at random between 0 and 1
- Using a fixed sequence
- How do we choose
- A small number, usually <0.5
Conclusion
Adding a penalty term to the objective function is equivalent to changing the fitness function, which, in turn, is equivalent to changing the selection probabilities. It is easier and more effective to change the selection probabilities directly and explicitly using Stochastic ranking and Feasibility rules.
We have also seen that there are alternative constraint handling techniques such as repairing methods.