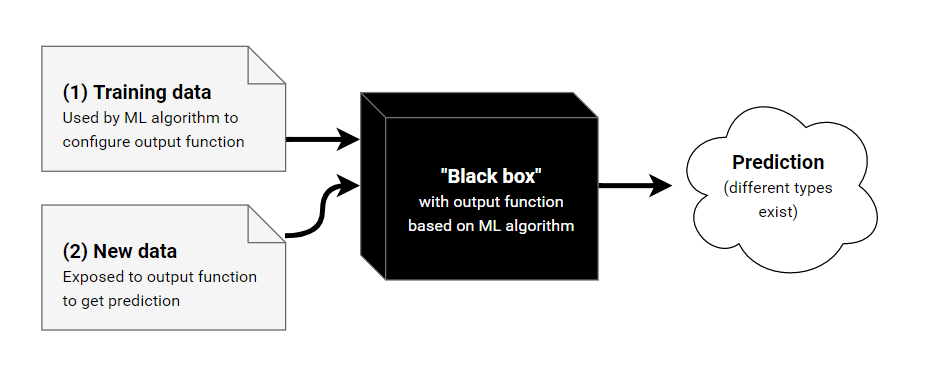
▶︎
all
running...
Lecture 2
Linear Regression Models
Cat Hearts example:
Experience
- The dataset consists of data points
- is the "input" for the data point as a feature vector with elements, being the # of dimensions in the feature space, in this case 1.
- is the "output" for the data point, in this case the weight of the corresponding cat heart.
Learning Task,
- In this example, our task is: Linear Regression
- Find a "model", i.e. a function:
- s.t. our future observations produce output "close to" the true output.
Linear Regression Model
- A linear regression model has the form:
- where:
- is the input vector (feature)
- is the weight vector (parameters)
- is a bias (parameter)
- is the predicted output
- In our cat example we have:
- as "body weight" is our only feature
- as from intuition we expect a cat of 0 weight to have a heart of 0 weight.
- Our model has one parameter:
Performance Measure,
- Want a function, which quantifies the error in the predictions for a given parameter
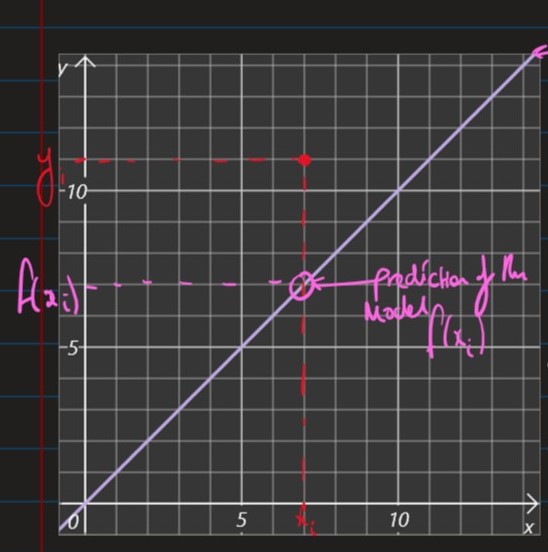
- The following empirical loss function, takes into account the errors data points.
- where the summation term is squared so that:
- we ignore the sign
- we penalise large errors more
- To find the optimum weight, solve:
- = 0
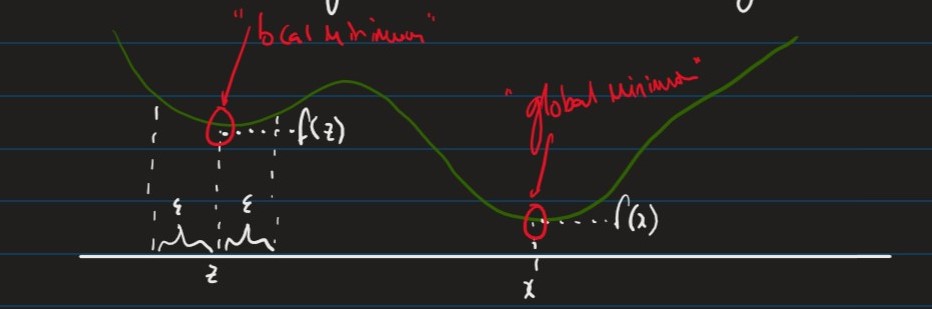
Unconstrained Optimisation (Minimisation)
Given a continuous function:
- , as our loss function
- an element is called:
- A global minimum of iff:
- A local minimum of iff:
- if
- A global minimum of iff:
Theorem:
For any continous function, , if is a local optimum,
Definition:
The derivative of a function is
Differentiation Rules
- = , if
- chain rule
Approach 1: Ordinary least squares
- Optimise by solving
-
-
- This only has one solution a global minimum.
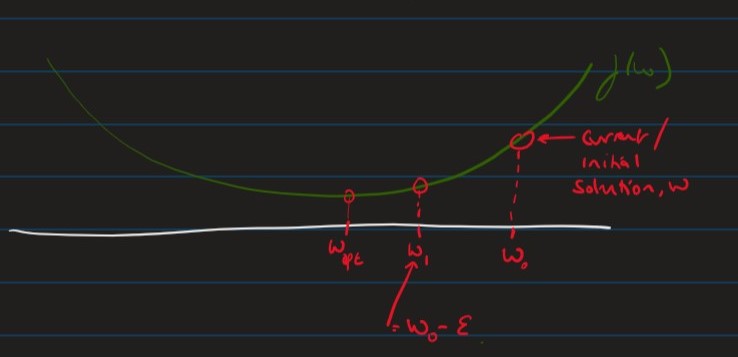
Approach 2: Gradient descent
- Often difficult / impossible to solve for non-linear models with many parameters
Idea:
-
Start with an initial guess
-
While :
- move slightly in the right direction
-
To make this viable we need to define:
- "what is the right direction?"
- "what is slightly?"
Attempt 1 (failed)
repeat:
if
elseif
- where is the learning rate set manually. (hyper-parameter)
Issue with this attempt:
- w may oscillate in the interval
- w fails to converge
Attempt 2: Gradient Descent (1D)
repeat:
if