In gradient descent we have an input of a cost function, J and a learning rate, ε
J:Rm→R
The pseudo-code for conventional gradient decent is as follows:
foo
x←some initial point in Rmwhile termination condition not met{x←x−ε⋅∇J(x)}
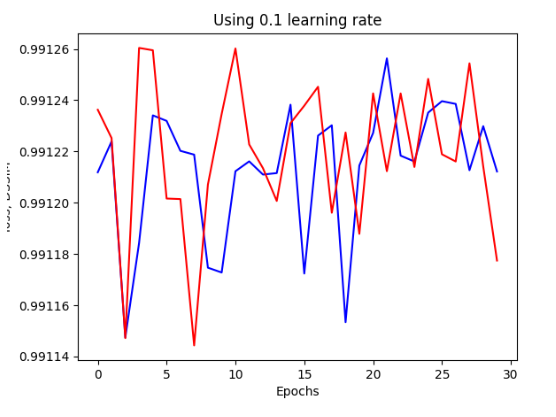
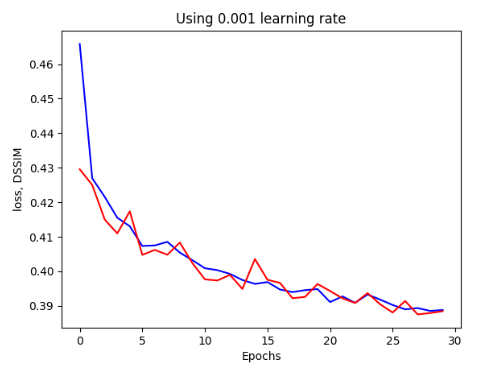
Impact of learning rate ε on Stochastic Gradient Descent
Learning rate in SGD can have a marked impact on the optimisation time of a network
Often necessary to vary/ adjust the learning rate according to the specific model you are training.
If a learning rate that is too high is used then the model parameters vary wildly causing a large variance in the value of the loss function, J
If too low a learning rate is used then the model stagnates far from the optimum conditions, it may converge given enough epochs but this would take exponentially long relative to the size of the learning rate
Gradient Descent with Momentum
Choose initial parameter, Θv=0while termination condition is not met{v=αv−E∇ΘC(Θ)Θ=Θ+v}
Conceptually, we can think of momentum in this context the same as in physics:
A Ball with position Θ and a velocity v influenced by two forces, one which pushes the ball in the opposite direction of the current gradient, and a viscous drag determined by a parameter α<1
The momentum smooths out the update steps. The size of the updates is proportional to how similar the previous gradients are.
Two Hyper-parameters
ε← learning rate
α← Factor which determines the influence of the past gradients on the current update of the parameter, typical values include 0.5, 0.9 or 0.99
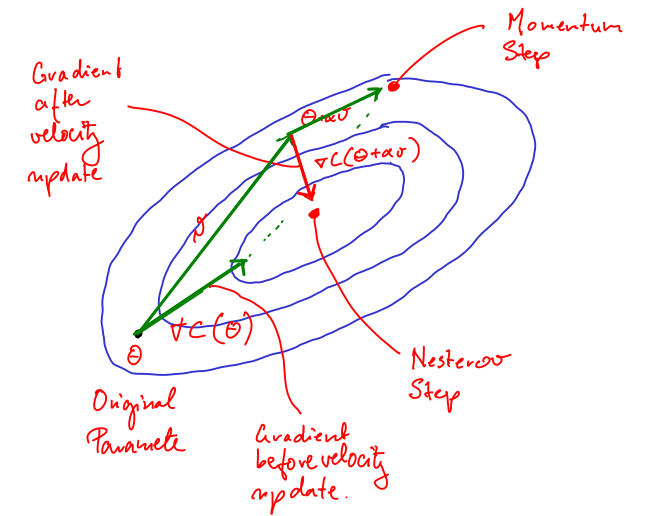
Nesterov Momentum
Choose an initial parameter, Θv=0While termination condition is not met{v=αv−ε∇C(Θ+αv)Θ=Θ+v}
Nesterov Momentum is a variant of standard momentum where the gradient is computed after the velocity is applied
Adagrad
Duchi et al. 2011
choose an initial parameter, Θr=0while termination condition is not met{g=∇ΘC(Θ)r=r+g⊙g← *Squared gradient* v=δ+rε⊙gΘ=Θ+v
Where δ is a hyperparameter, typically around 10−6
Adagrad adapts a (possibly differing) learning rateδ+rε for each dimension according to accumulated square gradient, r
Large r⟹ small δ+rε
Small r⟹ large δ+rε
AdaGrad works well for problems with sparse gradients
All gradients are weighted equally by r
Adam
Kingma and Ba, 2014
Choose an initial parameter, Θr=0,s=0,t=0while termination condition not met{t+=1g=∇ΘC(Θ)s=ρ1s+(1−ρ1)gr=ρ2r+(1−ρ2)g⊙gsn=1−ρ1ts,rn=1−ρ2trv=−ε⋅rn+δsnΘ=Θ+v
Here v is defined as the average gradient divided by the average squared gradient