Lecture 9
Previously, we looked at different optimisation algorithms.
Generalisation in Neural Networks
Hypothesis:
Neural Networks generalise from the training data, i.e. by learning the inherent structure in the data.
Test of Hypothesis: removing structure should reduce network performance
Zhang et al. (ICLR 2017) trained a network over the CIFAR10 dataset with the following settings:
- True labels, original training set (ground)
- Random labels: all labels are replaced with random ones
- Shuffle pixels: a random permutation of the pixels for each image
- Gaussian: A gaussian distribution is used to generate random pixels for each image
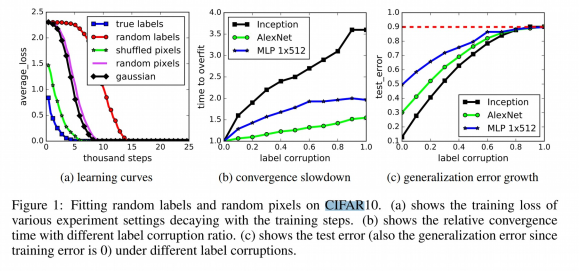
- Deep neural networks easily fit random labels
- The effective capacity of neural networks is sufficient for memorising the entire dataset
- Training time increases only by a small constant factor
Perceptrons
These were a very early form of artificial networks and are comparatively very weak to current approaches
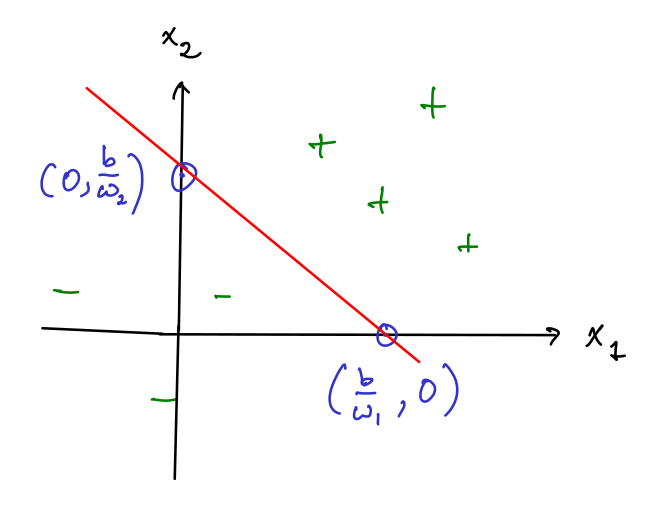
Linear decision Boundary
The boundary between positive and negative output of a single layer perceptron , can be described by a linear hyper-plane
For example, in 2D we get:
Minsky & Papet (1969)
A single layer perceptron cannot learn the XOR function
- Caused controversy and led to the "AI Winter"
Reduced research funding to Neural Network research
Reduced interest among researchers
Lebesgue Integration
THe Lebesgue Integral
This is an alternative to the Riemann Integram which is defined for more complex functions, .
It is defined with respect t a measurement which measures the size of subsets of the domain of
It can be defined as:
Given , let
then,
where the LHS is the Lebesgue Integral and the RHS is the Riemann Integral
Discriminatory Functions
Definition:
is called discriminatory iff
Lemma
Any function where:
is discriminatory
For example, the Sigmoid function is discriminatory
Theorem (Cybenko, 1989)
Let be any continuous discriminatory function, then for any function i.e continuous function on and any then there exists a finite sum of the form:
s.t.
Definition: Normed Linear Space
A Normed Linear Space is a vector space over and a function satisfying the following:
Definition Supremum Norm
We can now measure the distance between two functions and by
Closure
Let be a subset of a normed vector space . The closure of , , consists of all s.t. for each , we can find an element s.t.
For example the closure of the set of rational numbers, , is the set of real numbers, .
Defininition
A linear function on a real vector space, is a function s.t.
Theorem
Let be a normed linear space, can be a subspace of and
if ???? does not belong to the closure of then there exists a bounded linear functional s.t.
Proof
Let be the set of functions that can be described on the form .
The statement of the theorem is equivalent to the claim that the closure of =
Assume by contradiction that the closure of is a strict subset, of
It follows by the previous theorem that there must exist a linear functional s.t.
By the Riesz representation theorem, there exists a signed measure s.t.
Since , we have:
However, this contradicts our assumption that is discriminatory.
The theorem now follows
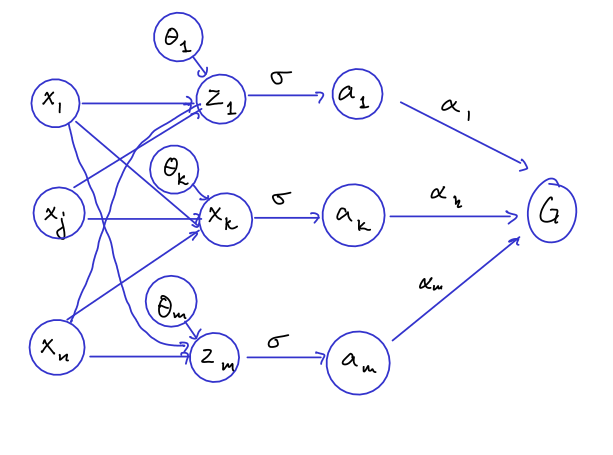
The power of depth
Cybenko's result does not tell us:
- how many units are needed in the hidden layer
- how difficult it is to tran the network to approximate the function
However it does tell us:
- This proof shows us that we can approximate any continuous function with a single layer.
Theorem (Eldan & Shamir, 2016)
If the activation function satisfies some weak assumptions, then there is a function and a probability measure on s.t.
- is "expressible" by a 3-layer network of width
- Every function, expressed by a 2 layer netowrk of width at most satisfies: